به زبانی ساده، ساختارهای داده یا همان Data Structures در جاوااسکریپت یک روش معنادار و از پیش تعیین شده جهت چیدن و ذخیره کردن داده ها در کامپیوتر هست تا بتونن در زمان نیاز پردازش و یا استفاده بشن که این Data structures در جاوااسکریپت را میتوان به دو دسته primitive data structure و non-primitive data structure تقسیم بندی کرد.
مقدمه ایی کوتاه برای درک بهتر Data Structures در جاوااسکریپت
قبل از اینکه بریم سراغ بخش های اصلی این مقاله، بیایید یه گپ و گفت و مروری بر انواع متغیرها در جاوااسکریپت و data type ها داشته باشیم و یک دوره دیگه هم data structures را به زبانی ساده باهم مرور کنیم.
- data type ها صرفا یک طبقه بندی و یا دسته بندی از انواع مختلف داده ها هستند و به ما نوع مقدار ذخیره شده در یک متغیر را میگن و مشخص میکنند که از چه عملیات ها و متدهایی میتونیم روی این نوع از متغیر و داده استفاده کنیم.
- data structure هم یک روشی برای ذخیره کردن داده ها در کامپیوتر به روشی منظم و از پیش تعیین شده هست تا در زمان مربوطه و نیاز اون داده اجرا و پردازش بشه و data structures را به دو گروهه primitive data structure and non-primitive data structure تقسیم میکنیم.
primitive data structure
این گروه فقط و فقط یک نوع از داده یعنی کاراکتر هارو میتونن ذخیره کنن.
ویژگی های کلیدی این گروه:
- سایز این گروه از اونجایی که فقط یک نوع مقدار رو میتونن ذخیره کنند مشخص هست.
- primitive data structures نمیتونن مقدار
nullرا ذخیره کنند و یا خالی باشن، حتما باید حاوی یک مقدار باشن. - اعداد، کاراکتر ها، اعداد اعشاری و boolean از مثال هایی هستند که primitive data type ها میتونن ذخیره کنند.
non-primitive data structures
این گروه، برخلاف گروه قبلی میتونن مقادیر مختلفی را ذخیره کنند.
- سایز این گروه بستگی به نوع مقداری که ذخیره کرده داره
- این گروه در زمان ایجاد شدن خالیه از هرگونه مقداری هستند و در نتیجه میتونن مقدار
nullرا هم ذخیره کنند. - lists, stacks, queues, dictionaries از نمونه مقادیری هستند که میتونن توی این گروه ذخیره بشن.
برخی از رایج ترین non-primitive data structures ها
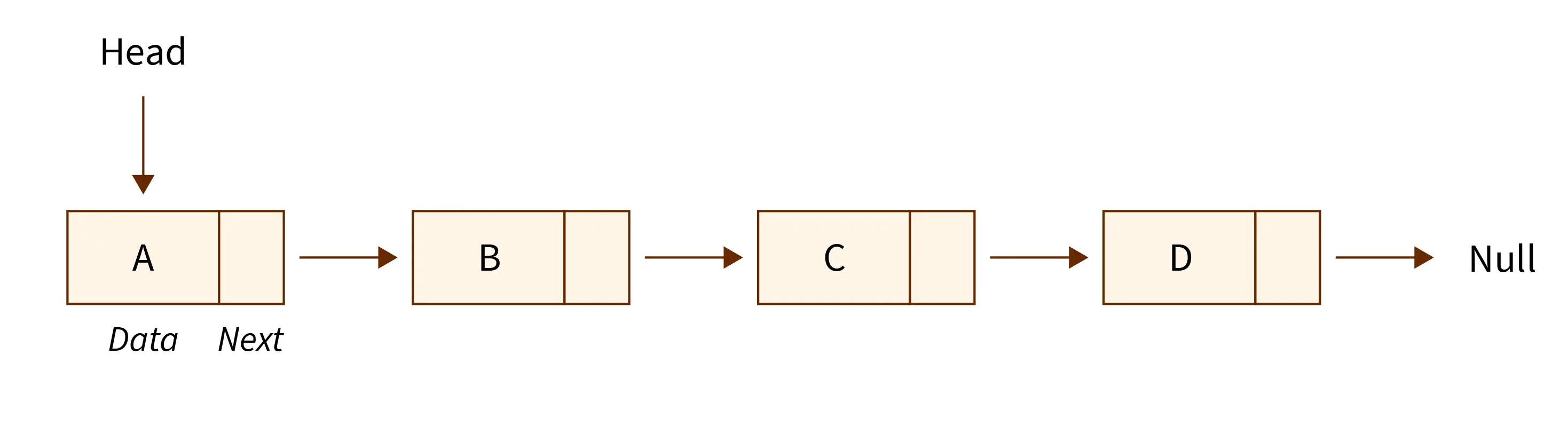
Linked List
همینطور که از اسم این آیتم پیداست، linked list به مجموعه ای متوالی از عناصر داده که از طریق لینک ها به هم متصل می شن اشاره داره. هر آیتم از این لیست را به عنوان یک node میشناسیم و هر node هم شامل دو بخش 1. data part ( بخش داده ایی ) 2. pointer ( اشاره گر ) هست.
data part شامل مقدار حقیقی داده هست و pointer هم به آیتم بعدیه لیست اشاره میکنه.
نکته: node آخر لیست به null اشاره داره.
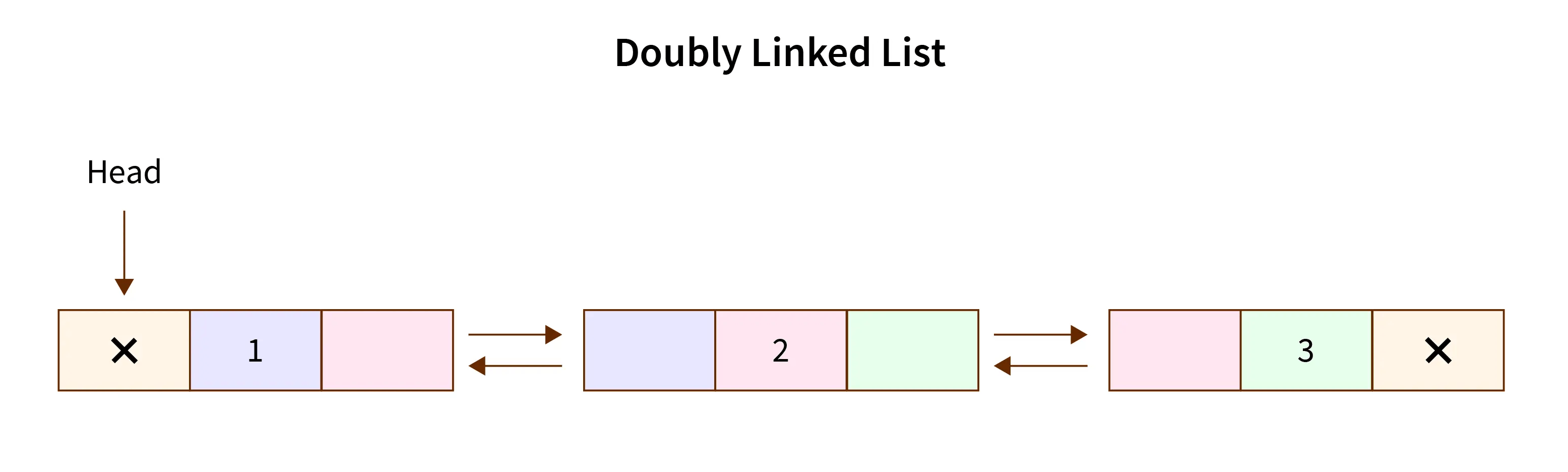
Doubly Linked List
doubly linked list هم مثل مورد قبل به مجموعه ای متوالی از عناصر داده که از طریق لینک ها بهم متصل اند اشاره داره. هر node در این گروه شامل سه بخش هست، خود داده و دوتا pointer که طبیعتا یکی از pointer ها به node بعدی و یکی دیگه هم به node قبلی اشاره داره.
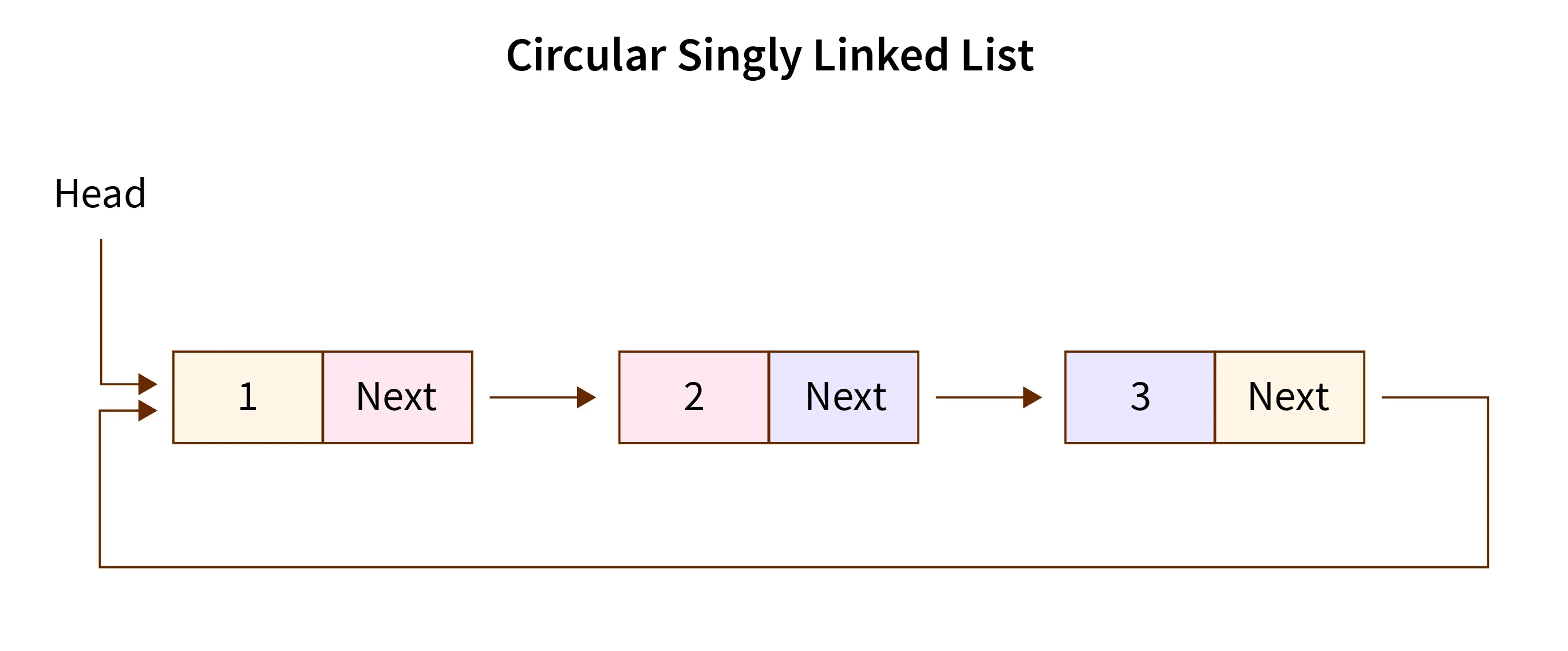
Circular Linked List
به مجموعه ای متوالی از عناصر داده که از طریق لینک ها به هم متصل می شن اشاره داره. هر آیتم از این لیست را به عنوان یک node میشناسیم و هر node هم شامل دو بخش 1. data part ( بخش داده ایی ) 2. pointer ( اشاره گر ) هست و تفاوتش با linked list در آخرین pointer هست و آخرین pointer به اولین node اشاره میکنه و از اینرو اسم این گروه circular linked list به معنای لیست دایره ایی هست.
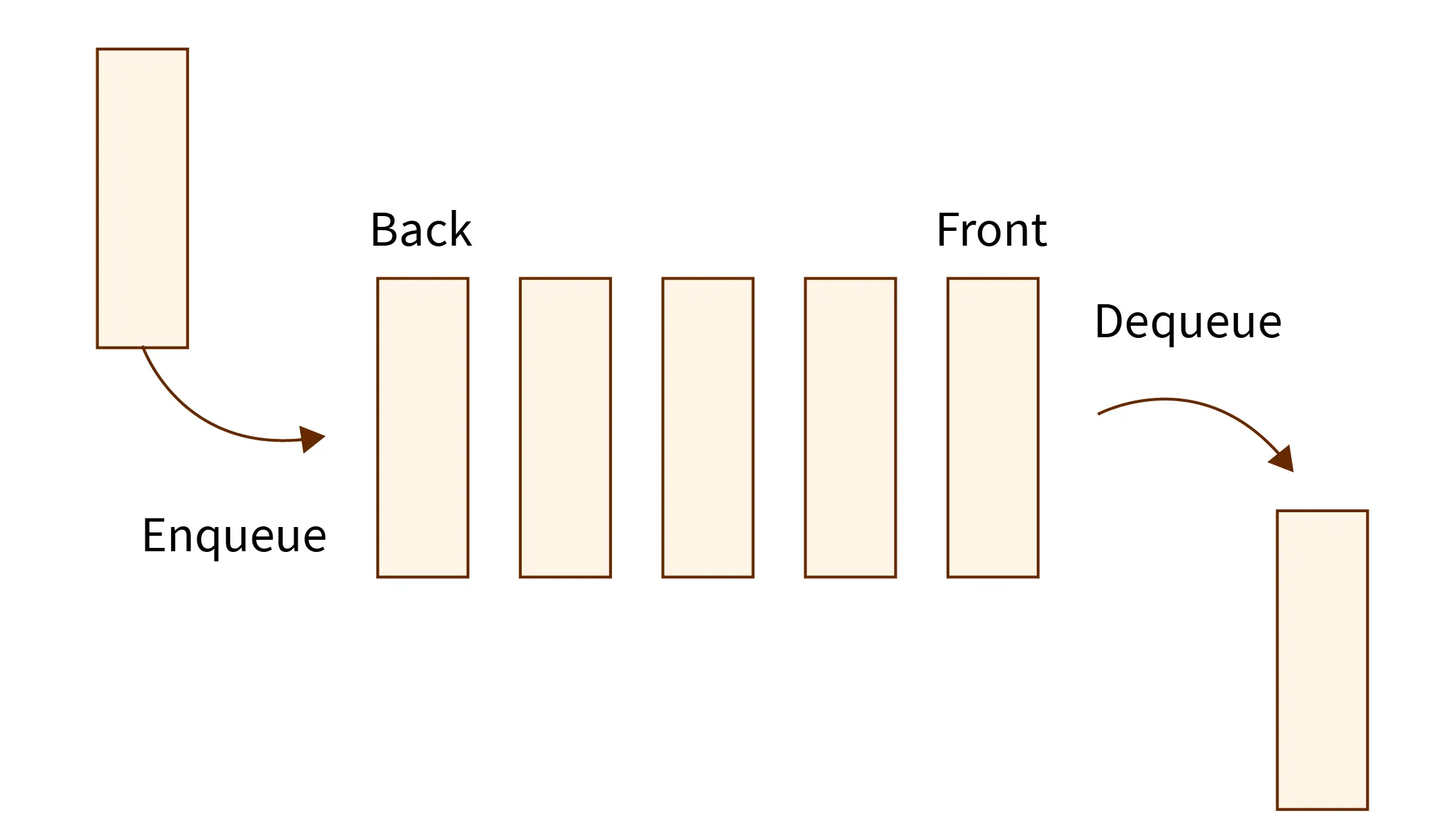
Queue ( صف )
queue های خطی، داده هارو بطور متوالی و با الگوی First In First Out ( FIFO یا اولین ورودی، اولین خروجی ) ذخیره میکنند. بنابر این اولین داده ایی که وارد میشه، به عنوان اولین داده هم از صف خارج میشه. از اینرو اونهارو حتی با اصطلاح First Come First Served ( اولین ورودی، اولین پردازش ) هم شناخته میشن.
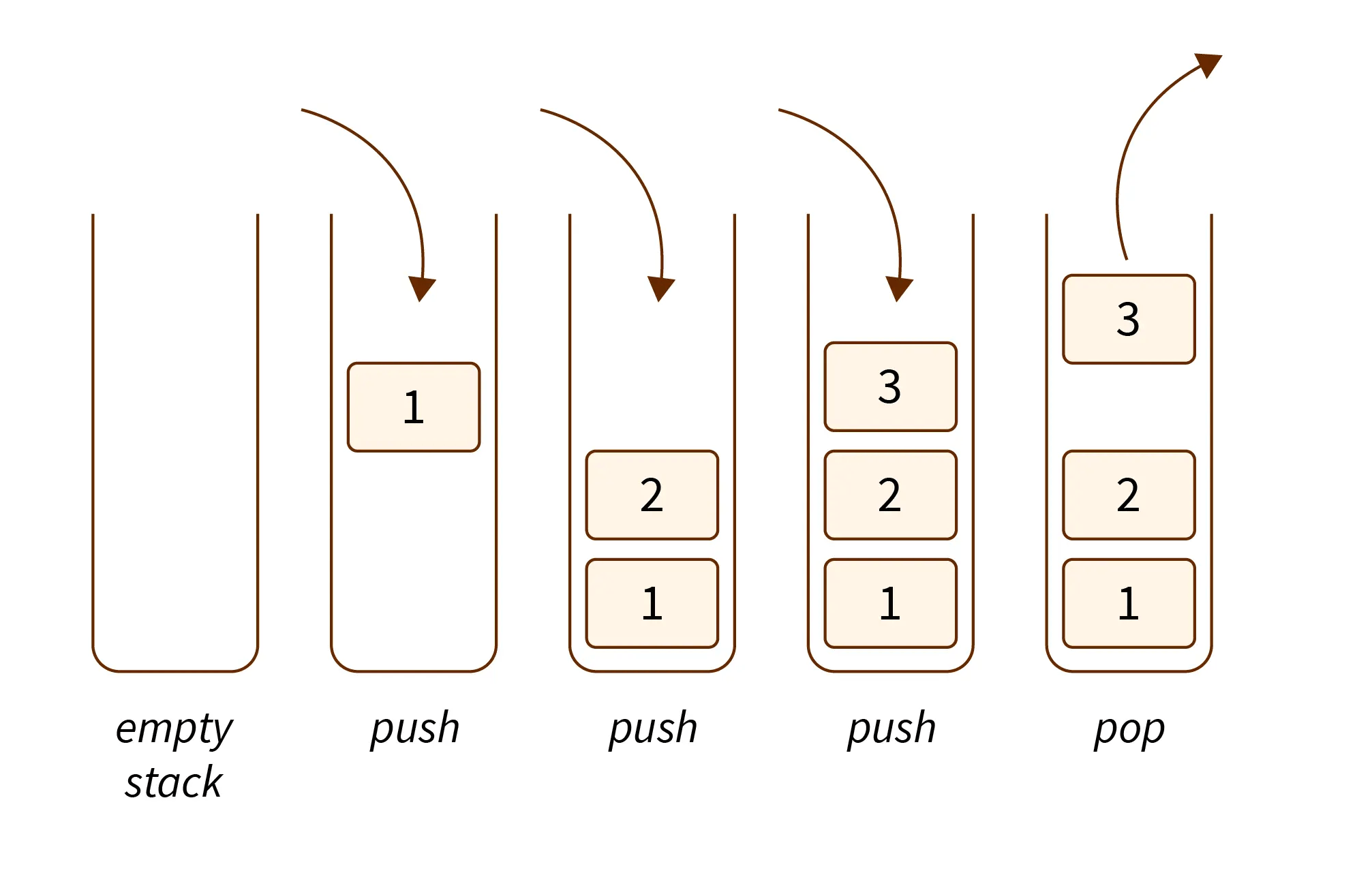
Stack
stack خطی، داده هارو بطور متوالی و طبق الگوی Last In First Out ( LIFO یا آخرین ورود، اولین خروج ) ذخیره و پردازش میکنند.بنابر این داده ایی که اول وارد بشه، آخر پردازش میشه و از اینرو این الگو را حتی با عنوان Last Come First Served ( آخرین ورود، اولین پردازش ) هم میشناسیم.
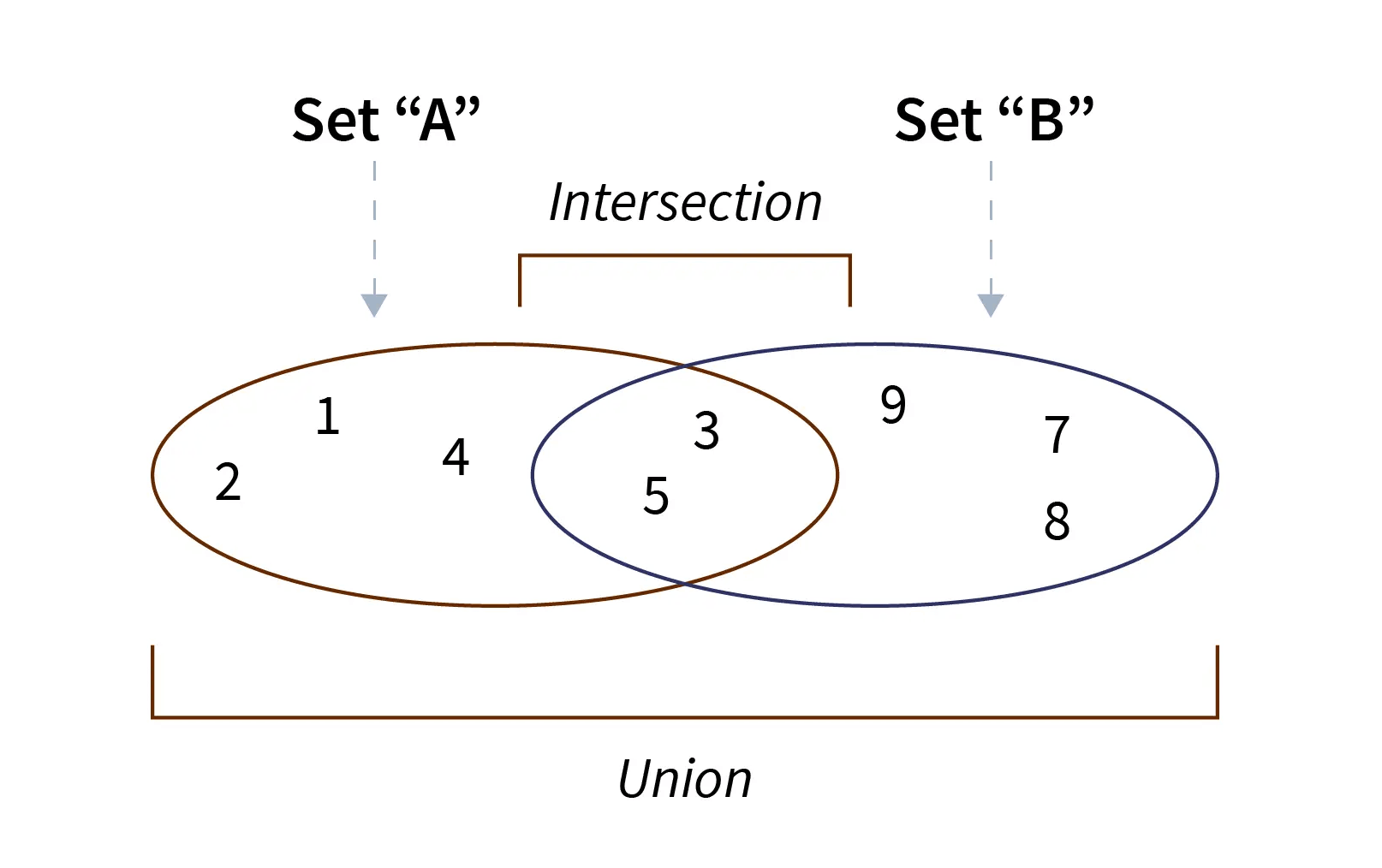
Set
set data structures در جاوااسکریپت مشابه set های ریاضی هستند. به زبانی ساده تر میشه گفت که set مثل یک جعبه ایی برای ذخیره کردن مقادیر هست با این تفاوت که تمام مقادیری که در اون ذخیره میشن باید یکتا و منحصر به فرد باشن و داده تکراری نمیتونه توی اونها ذخیره بشه.
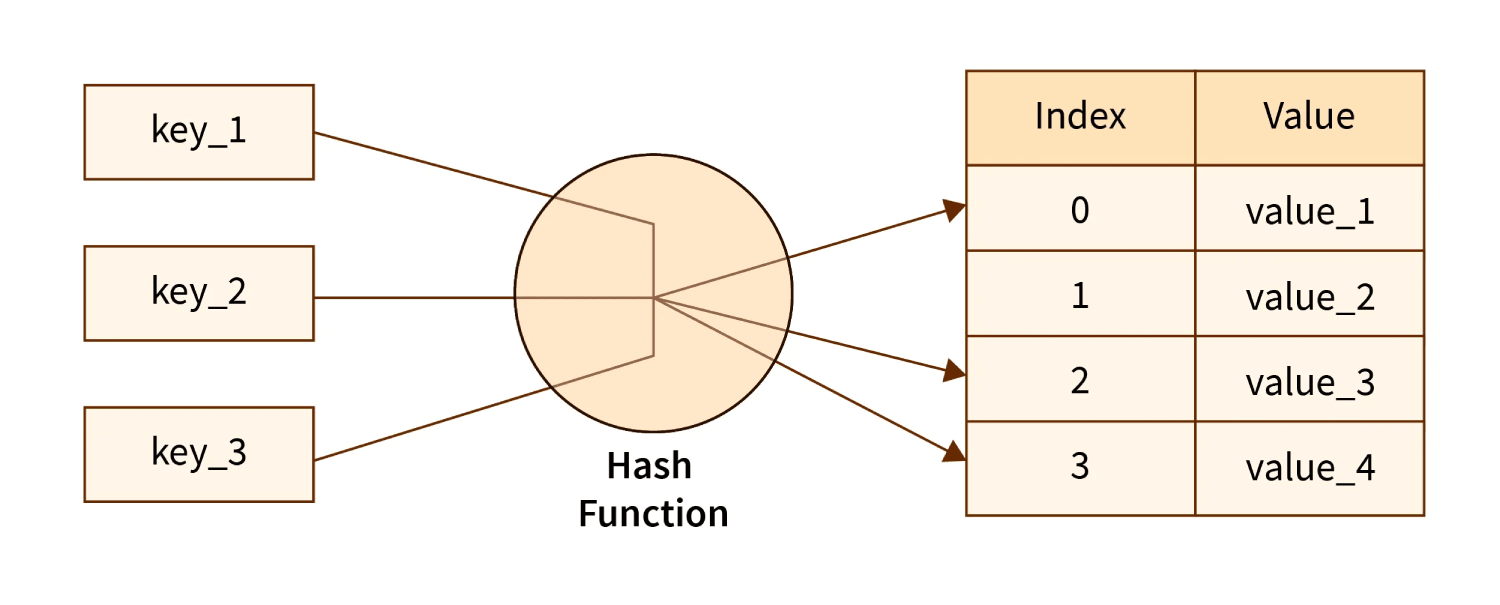
Hash Table
hash table یکی از مهمترین و پر استفاده ترین data structure در جاوااسکریپت هست. hash table داده هارو بصورت جفت های key:value ذخیره میکنه. این جفت های key-value باعث میشن تا بتونیم سریعتر داده مدنظر را دریافت کنیم و از key به عنوان index هر value استفاده میکنه. همچنین hash tables از یک فانکشن به نام hash function جهت مرتبط کردن key به value استفاده میکنه.
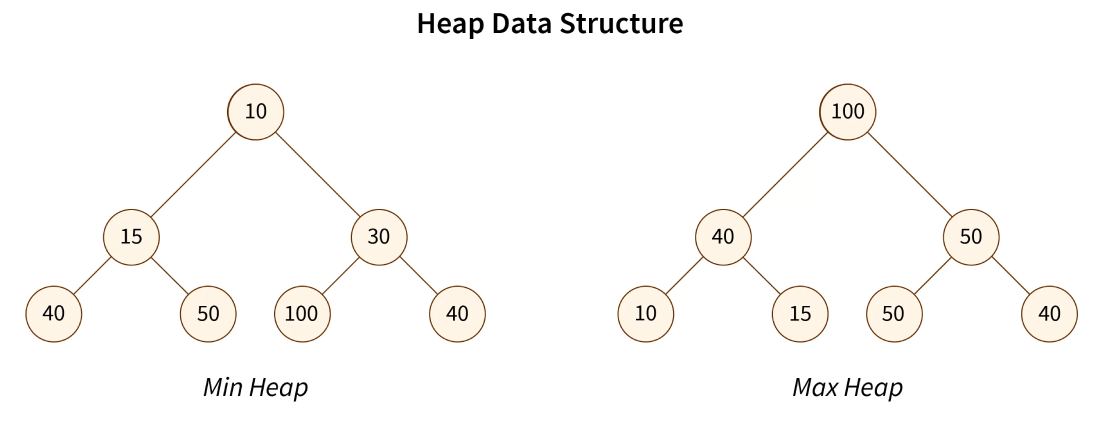
Heap - ورژن های Min و Max از Heap
همچنین heap یک non-linear tree-based data structure ( ساختار داده غیر خطیه درختی ) هست که داده هارو در شکلی از node ها ذخیره میکنه.heap data structure یک binary tree ( درخت باینری ) کامل را تشکیل میده. مزیت اصلیه استفاده از heap اینه که heap داده هارو با یک نظم خاصی ذخیره میکنه و با توجه به ترتیب داده ها ممکنه اونارو به دو گروهه Max Heap و Min Heap تقسیم کنه.
Min Heap: مقدار هر node کوچکتر یا مساویه مقادیر node های زیرمجموعش ( فرزندش ) هست.
Max Heap: مقدار هر node بزرگتر یا مساویه مقادیر node های زیر مجموعش ( فرزندش ) هست.
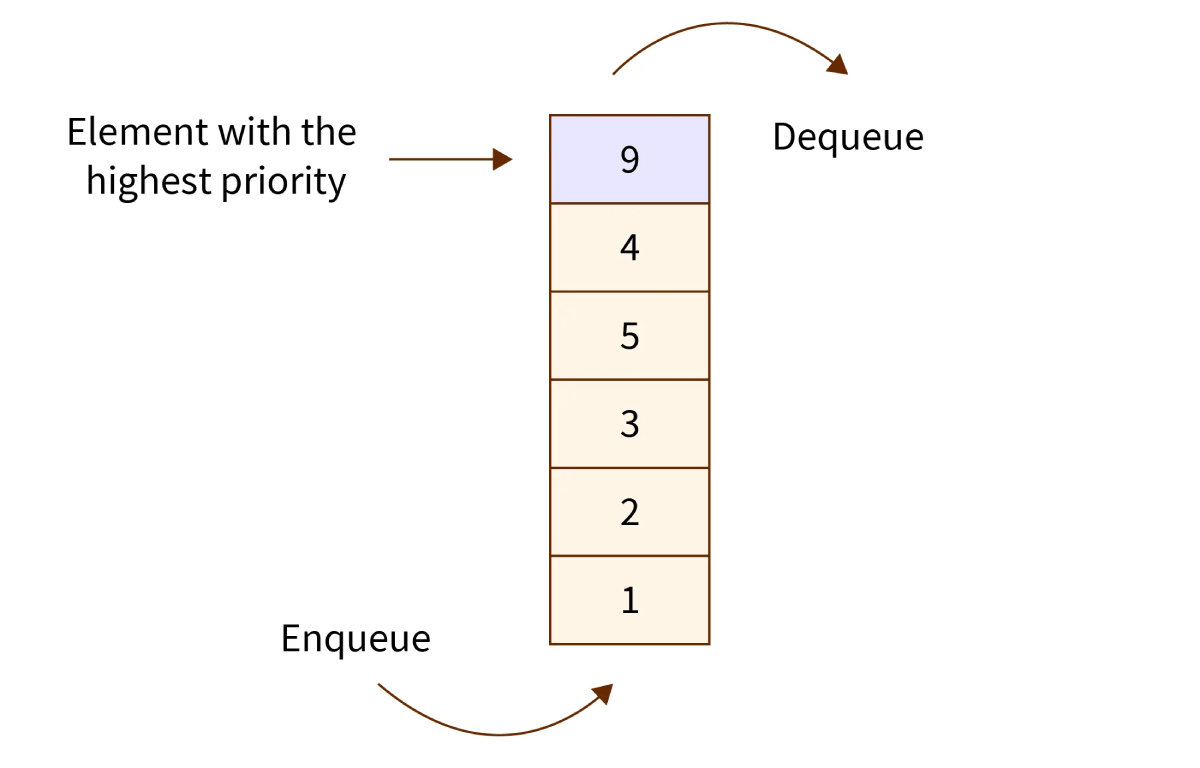
Priority Queue
priority queue یجورایی مشابه queue data structure هست با این تفاوت که هر آیتم از priority queue data structure با یک priority ( درجه اولویت ) مرتبط هست و با توجه به این اولیت ها مشخص میشه که کدوم آیتم اول پردازش میشه.
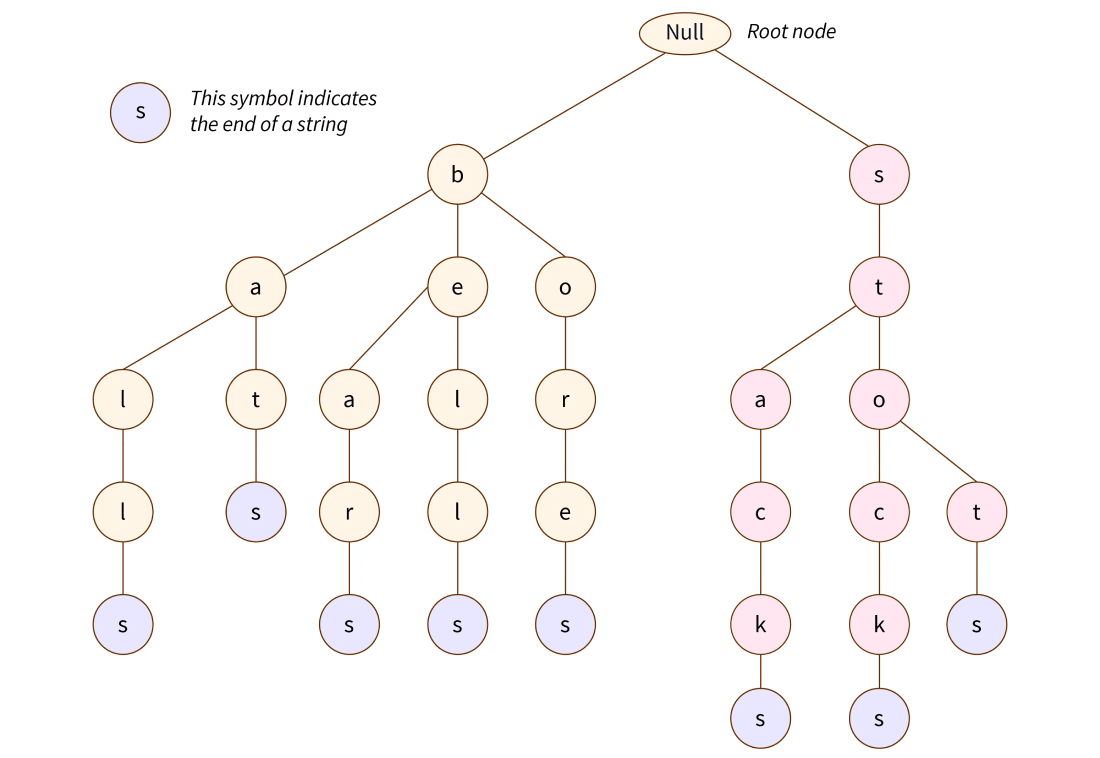
Trie
trie یک non-linear data structure ( ساختار داده غیر خطی ) هست که شباهت زیادی هم به ساختارهای درختی که از node ها تشکیل شدن داره و از این جهت حتی trie هارو با اصطلاح tree-like هم میشناسیم. بیشترین استفاده از trie data structure برای جستجو ها استفاده میشه. به عنوان مثال میتونیم یک دیکشنری را در غالب این ساختار داده ذخیره کنیم و سپس از اون جهت فراهم کردن لیستی از کلمات و پیشنهادات استفاده کنیم.
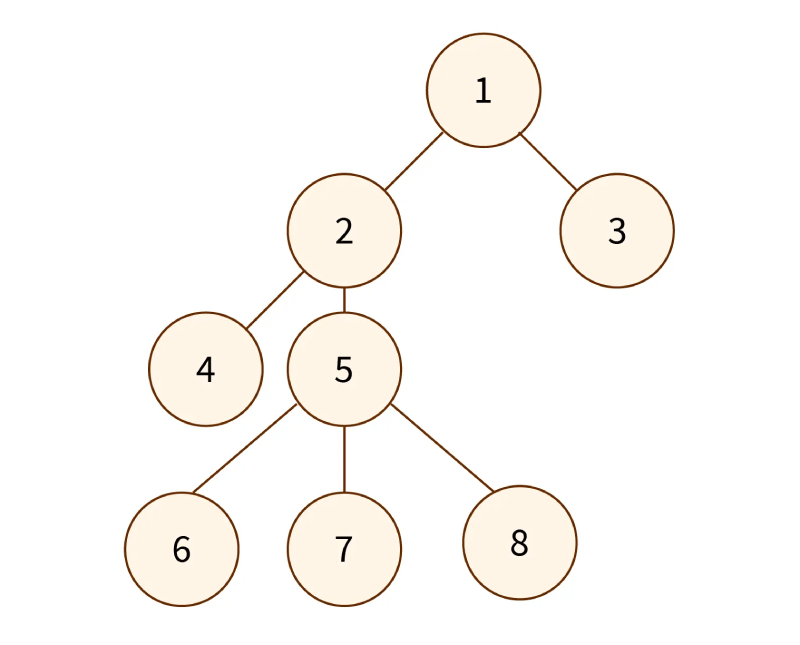
Tree
ساختار داده Tree یک ساختار غیر خطیه بر اساس سلسه مراتب یا به انگلیسی hierarchical non-linear data structure هست که برای سازمان دادن، ذخیره کردن و دستکاری کردن داده ها بکار میره. پیمایش درختی در ساختار داده یک تکنیکی هست که برای پیمایش و یا مشاهده node های یک ساختار درختی بکار میره. ( برای چاپ و دستکاری کردن )
تمام node های یک tree ساختار hierarchal structure را تشکیل میدهند ( یا به عبارتی همه اونها از طریق edges یا همان لبه ها بهم متصل میشن ) و ما میتونیم به آسانی از طریق node اصلی یا head node تمامی node هارو پیمایش کنیم.
Binary Tree
binary tree data structure ساختاری هست که در آن هر node فقط میتونن دوتا node فرزند داشته باشن.
Binary Search Tree
یک binary search tree در واقع یک binary tree هست که در آن هر آیتم حداکثر دو node فرزند دارند.
تمام node های سمت چپ باید کوچکتر یا مساویه node والد خود باشند و از طرفی هم تمام node های سمت راست باید بزرگتر یا مساویه node والد خود باشند.
AVL Tree
AVL tree (Adelson-Velsky and Landis tree) یک binary search tree با ماهیت self-balancing هست و خاصیت اصلی AVL Tree این هست که ارتفاع سمت چپ نمودار نمیتونه بیشتر از سمت راست خودش باشه.
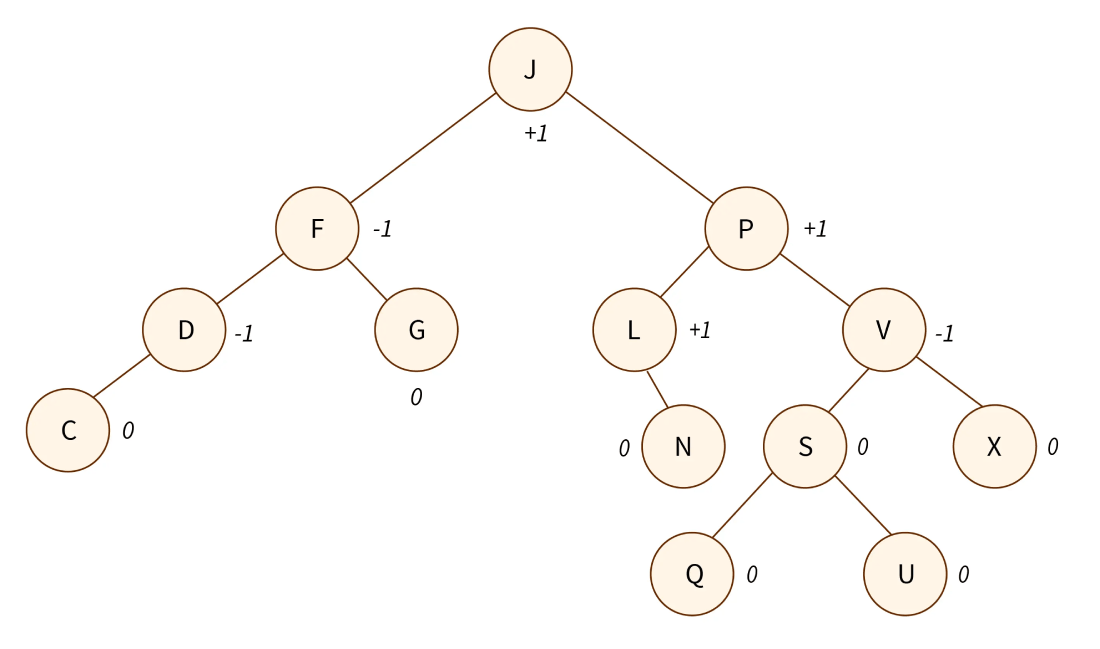
Red-Black Tree
red-Black tree هم یک binary search tree با ماهیت self-balancing هست و هر node از این ساختار یا قرمزه یا مشکی.
- Leaf Node ها مشکی هستند ( یعنی تمام node های بدون فرزند مشکی در نظر گرفته میشن، همچنین اونارو با نام NIL هم میشناسیم )
- اگر node والد قرمز باشه، تمامی node های فرزندش باید مشکی باشن
- هر مسیر از node ها به leaf node های فرزند باید به تعداد یکسان node مشکی داشته باشن.
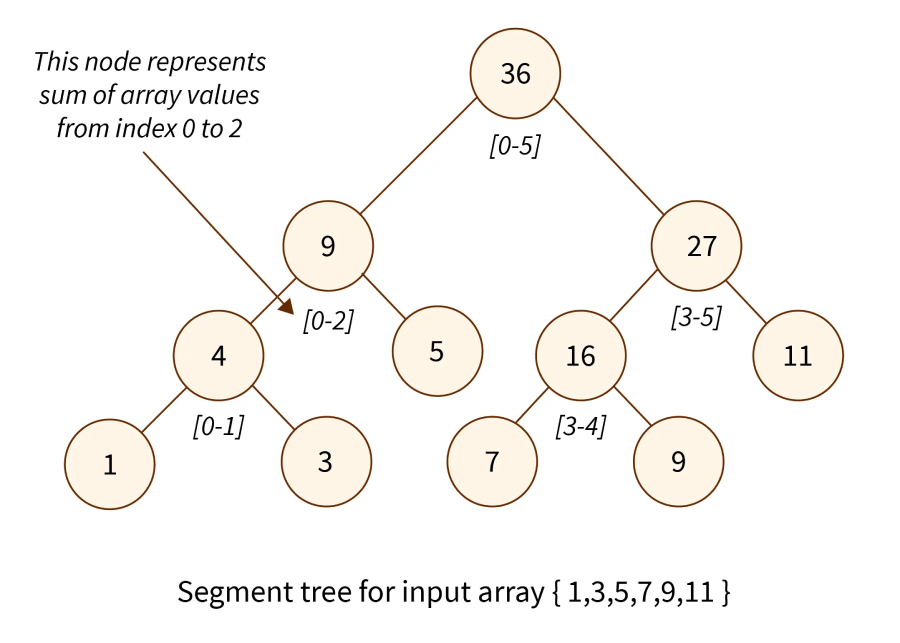
Segment Tree
segment tree یا statistic tree ( درخت آماری ) یک ساختار داده درختی هست که ازش برای ذخیره کردن اطلاعات فواصل یا بخش ها استفاده میشه.
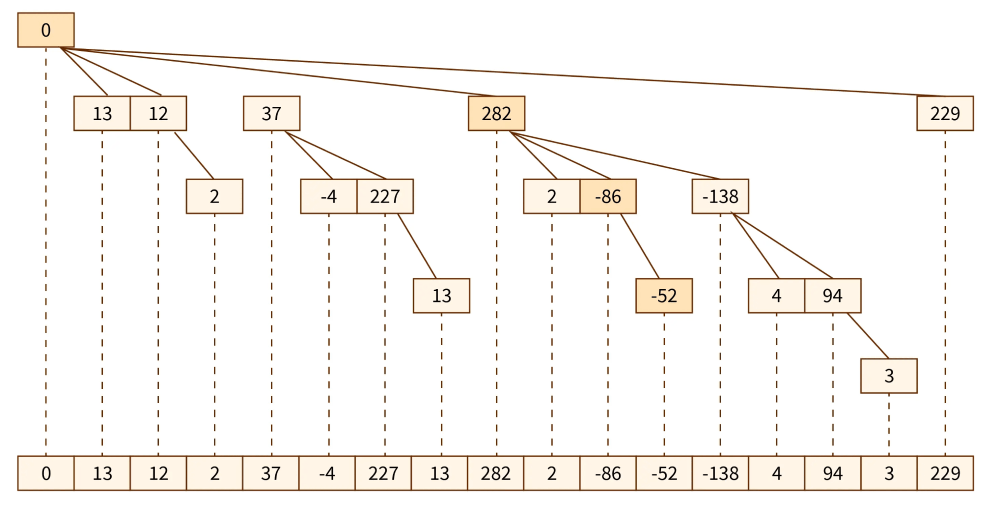
Fenwick Tree (Binary Indexed Tree)
fenwik tree یا Binary Indexed Tree یک array-like structure هست که ما میتونیم توش آیتم هامون رو مثل آرایه ها به آخر tree اضافه کنیم.Fenwick Trees ها راحت تر ایجاد میشن و فضای کمتری رو هم نسبت به segment tree ها اشغال میکنند.
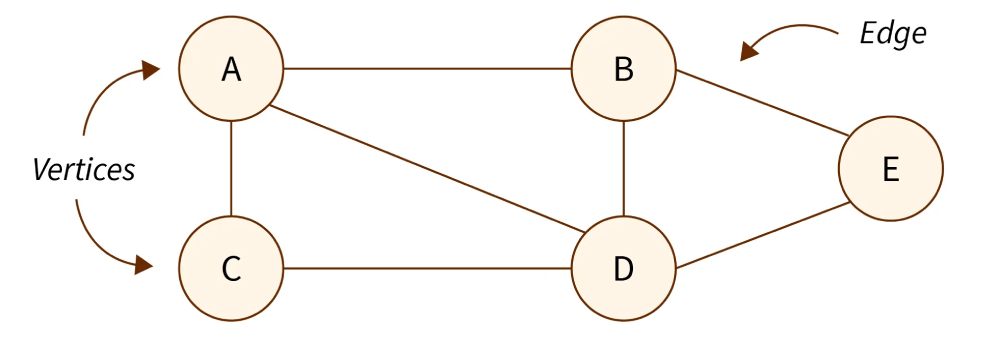
Graph
Graph ها ساختاری رابطه محور و غیر خطی ( relationship-based non-linear data structures ) هستند که از طریق node های متصل از طریق لبه ها ایجاد میشن. همچنین هر node در graph به عنوان vertex هم شناخته میشه.
نماد معرف یک graph هم G = (V, E) هست که V مجموعه ایی از تمام vertices ( رگه ها ) هست و E هم مجموعه ایی از edge ( لبه ها ) هست.